1 Linux初探,打开新世界的大门

视频课程地址:https://ke.qq.com/course/288048?tuin=20cd7788
1.1 Linux系统简介和目录理解
1.1.1 为什么要用Linux系统
个人认为,Linux操作系统和类Linux操作系统的命令行界面是最适合进行生物信息分析的操作系统。原因有三点:
- 长期运行的稳定性
- 多数软件只有Linux版本
- 强大的Bash命令简化繁琐的操作,尤其是大大简化重复性工作
但对于初学者来说,接触和理解Linux操作系统需要一些时间和摸索。陡然从可视化点选操作的Windows进入到只有命令行界面的Linux,最大的陌生感是不知道做什么,不知道文件在哪?
我们这篇教程就带大家学习、熟悉、体会Linux系统的使用。
1.1.2 Linux系统无处不在
Linux是一种多用户、多任务的操作系统。最开始是由Linus Torvalds与1991年发布,后由社区维护,产生了不同的分发版。
常见版本有
Centos,Ubuntu,RedHat,Debian等。服务器多用Centos系统,免费,稳定,但更新慢。Ubuntu系统更新快,注重界面的体验,适合自己笔记本安装。有面向中国的“麒麟”系统。其它两个没用过,Centos与RedHat,Debian与Ubuntu同宗,命令行操作起来很相似。
1.1.3 免费的Linux系统来一套
- 如果自己的单位有共有服务器,可以尝试申请账号。
- 自己的电脑安装双系统或虚拟机。
- 使用gitforwindows在windows下模拟使用Linux命令。
- 购买一块云服务器
- 试验下在线学习平台实验楼 https://www.shiyanlou.com (里面也有不少Linux教程,任意点一个进去,双击桌面的
Xfce图标,都可以启动Linux终端) - 这里有2个免费Linux系统等你来用
1.1.4 Linux系统登录-联系远方的她
登录服务器的IP是:192.168.1.107; 端口是:22;用户名是每个人的姓名全拼,如陈同为chentong (全小写,无空格);密码是 yishengxin。
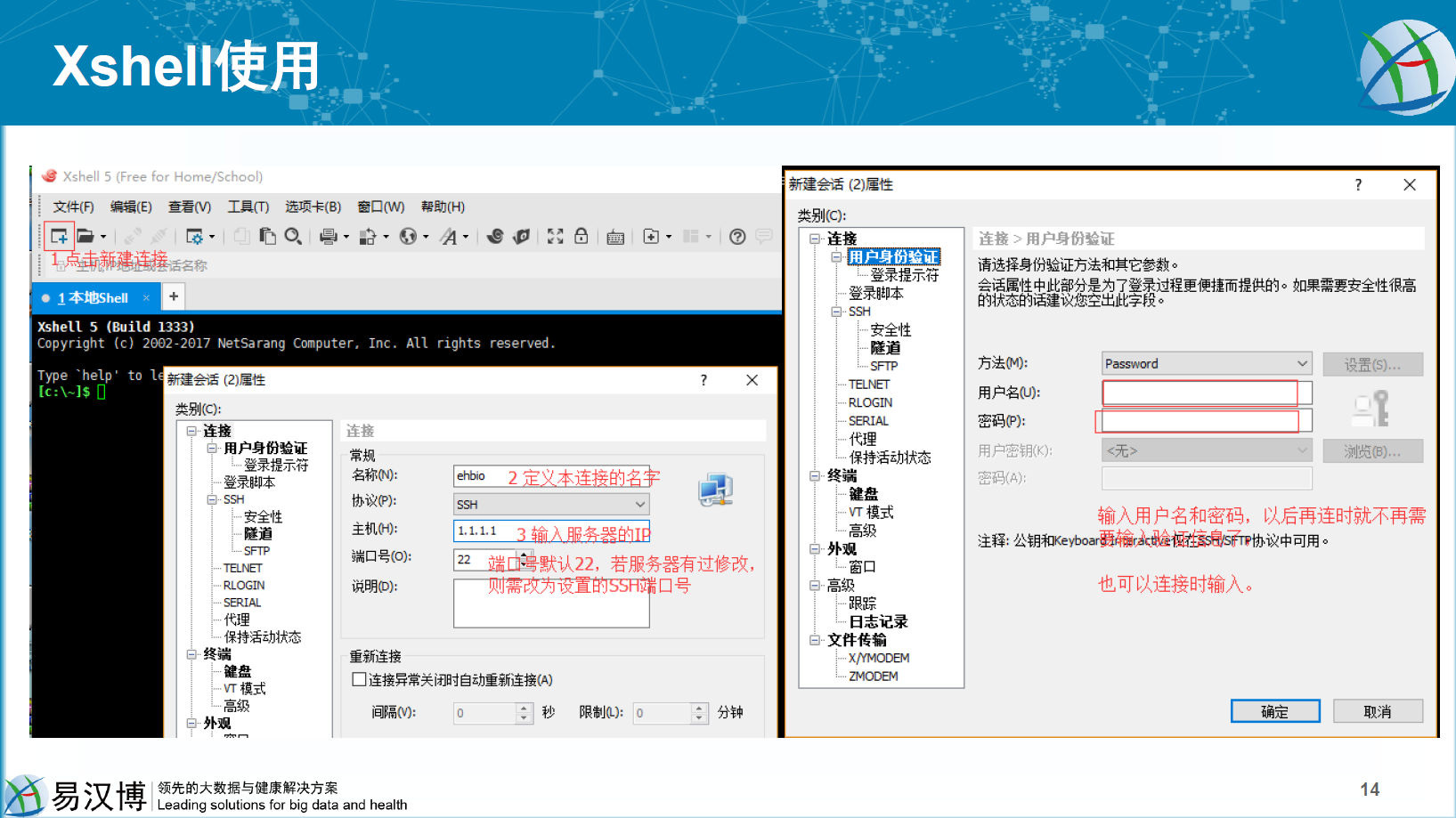
Figure 1.1: 配置Xshell登录服务器1。
Figure 1.2: 配置Xshell登录服务器2。
1.1.5 初识Linux系统 - 黑夜中的闪烁是你的落脚点
既然用Linux,我们就摒弃界面操作,体验其命令行的魅力和庞大。后续操作都是在命令行下进行的,主要靠键盘,少数靠鼠标。
登录Linux系统后,呈现在眼前的是这样一个界面:
首先解释下出现的这几个字母和符号:
ct: 用户名ehbio:如果是登录的远程服务器,则为宿主机的名字;若是本地电脑,则为自己电脑的名字。~: 代表家目录, 在我们进入新的目录后,这个地方会跟着改变$: 用来指示普通用户输入命令的地方;对根用户来说一般是#- http://bashrcgenerator.com/可视化定制不同的显示方式。
- 个人习惯的展示:
PS1=\[\e]0;\u@\h: \w\a\]${debian_chroot:+($debian_chroot)}\u@\h:\w\$ - 闪烁的光标处是你敲打键盘体验威力的地方 - 输入命令并按回车。
1.1.6 我的电脑在哪?
打开Windows,首先看到的是桌面;不爱整理文件的我,桌面的东西已经多到需要2个屏幕才能显示的完。另外一个常用的就是我的电脑,然后打开D盘,依次点开对应的文件夹,然后点开文件。
Linux的文件系统组织方式与Windows略有不同,登录进去就是家目录,可视为Windows下的桌面[^Linux的家目录严格来说可能类似于Windows下的`C:\\Users\\ct`]。在这个目录下,我们可以新建文件、新建文件夹,就像在桌面上的操作一样。
而Linux的完整目录结构如下:
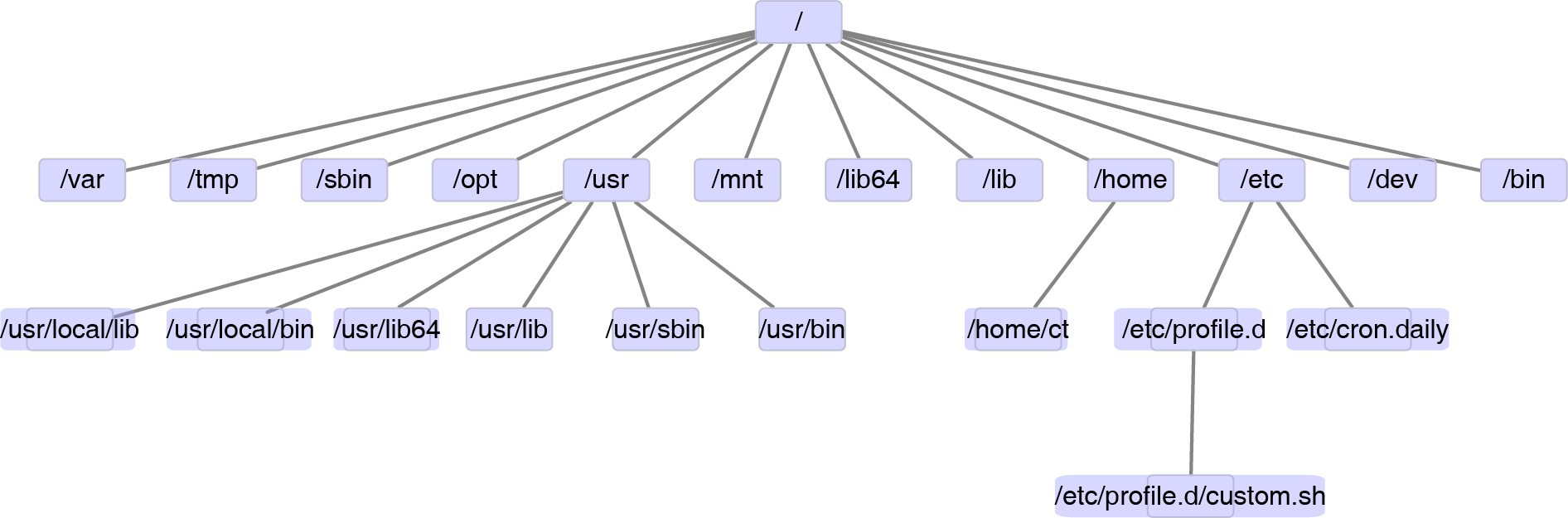
Figure 1.3: Linux目录层级结构。
| Path | Description |
|---|---|
| / | 根目录 |
| /bin | 常用软件如ls, mkdir, top等的存放地 |
| /dev | 硬件相关 |
| /etc | 存放系统管理和配置相关文件 |
| /etc/cron* | 与定时任务相关的文件夹,可执行程序放置到对应文件夹就可以定时执行 |
| /etc/profile.d | 目录下存放Bash相关的配置文件,相当于全局的.bashrc |
| /etc/profile.d/custom.sh | 我在配置全局环境时,一般写入这个文件;如果不存在,可以新建。 |
| /home | 家目录,默认新建用户的个人家目录都在此文件夹下 |
| /home/ct | 用户名为ct的用户的家目录 |
| /lib -> usr/lib | 存放动态库的目录 (library),安装软件时碰到依赖的动态库一般存储于此 |
| /lib64 -> usr/lib64 | 64位软件动态库,-> 表示软连接,等同于快捷方式 |
| /mnt | 文件系统挂载,一般插入U盘会显示在这。 |
| /opt | 部分额外安装的软件会置于此 |
| /root | 根用户的家目录 |
| /sbin -> usr/sbin | 根用户的管理命令 |
| /tmp | 临时目录,会定时清空,常用于存放中间文件 |
| /usr | 存放系统应用的目录,前面有几个目录都是该目录下子目录的软链 |
| /usr/bin | 大部分应用程序安装于此 |
| /usr/sbin | 根用户的管理命令 |
| /usr/lib | 存放动态库的目录 (library),安装软件时碰到依赖的动态库一般存储于此 |
| /usr/lib64 | 64位软件动态库 |
| /usr/local/bin | 存放本地安装的命令 |
| /usr/local/lib | 存放本地安装的库 |
| /var | 存放各服务的日志文件。若装有网络服务,一般在/var/www/html下。 |
作为一个普通用户,通常只在/home/usr, /tmp下有可写的权限,其它目录最多是可读、可执行,部分目录连读的权限都没有。这种权限管理方式是Linux能成为真正多用户系统的一个原因。后面我们会讲解如何查看并修改这些权限。
1.1.7 系统配置怎样?来看看256M硬盘的服务器
看完目录结构了,来看一下硬盘有多大,有多少可用空间,只需要运行df -h命令。
除了看硬盘,还想看下CPU、内存、操作系统呢?
Hostname is localhost.localdomain,Ip address is 192.168.1.30.
The 64 bit operating system is CentOS release 6.9 (Final),
Nuclear info is 2.6.32-696.10.1.el6.x86_64.
The CPU is Intel(R) Xeon(R) CPU E9-5799 v2 @ 3.90GHz.
There are 8 physical cpu, each physical cpu has 0 cores, 0 threads.
There are 96 logical cpu.
The memory of this server is 252G.1.1.8 看下目录下都有什么
通常登陆后直接进入家目录,下面大部分操作也是在家目录下完成的。如果想查看当前目录下都有什么内容,输入命令 ls,回车即可 (ls可以理解为单词list的缩写)。当前目录下什么也没有,所以没有任何输出。
如果错把l看成了i,输入了is,则会出现下面的提示未找到命令。如果输入的是Linux基本命令,出现这个提示,基本可以判定是命令输入错了,瞪大眼睛仔细看就是了。 在敲完命令回车后,注意查看终端的输出,以判断是否有问题。
当前目录下只有一个文件,看不出效果,我们可以新建几个文件和文件夹。
1.1.9 新建一个目录
mkdir是新建一个目录 (make a directory);data是目录的名字。
如果目录存在,则会出现提示,“无法创建已存在的目录”。这时可以使用参数-p忽略这个错误。
cat是一个命令,主要用来查看文件;在这与<<END连用用于读入大段数据。输入cat <<END之后,回车,会看到终端出现一个大于号,大于号后面可以输入内容,再回车,继续输入内容,直到我们输入END (大写的,与上面一致),输入过程结束,我们输入的内容都显示在了屏幕上。
如果我们想把这些内容写入文件,就需要使用 command > filename格式。
>是一个重定向符号,即把前面命令的输出写入到>后面的文件中。如下所示,新建了一个Fasta格式的文件。
ls -l列出文件的详细信息;-l表示命令行参数,是程序预留的一些选项,保证在不更改程序的情况下获得更灵活的操作。可使用man ls查看ls所有的命令行参数, 上下箭头翻页,按q退出查看。(man: manual, 手册)
1.1.10 访问文件
查看写入的文件的内容,cat 文件名;需要注意的是文件所在的目录,默认是当前目录;如下面第一个命令,会提示cat: test.fa: 没有那个文件或目录,是因为当前目录下不存在文件test.fa。(注意文件末尾的end)
test.fa在目录data下,可以先进入data目录,然后再查看文件。类比于Windows下先点开一个文件夹,再点开下面的文件。
这个例子中文件test.fa在当前目录的子目录data里面,在当前目录下直接查看test.fa就像在我的电脑里面不进入C盘,就像打开Program file文件夹。这属于隔空打牛的境界,不是一般人能练就的。起码Linux下不可以。
提到目录,Linux下有绝对路径和相对路径的概念。
绝对路径:以
/开头的路径为绝对路径,如/home/ct,/usr/bin,/home/ct/data等。需要注意的是~/data等同于/home/ct/data, 多数情况下可以等同于绝对路径,但在一个情况下例外,软件安装时用于--prefix后的路径必须是/开头的绝对路径。相对路径: 不以
/和~开头的路径都是相对路径,如data表示当前目录下的data目录,等同于./data(.为当前目录),../data表示当前目录的上一层目录下的data目录 (../表示上层目录)。
pwd (print working directory) 获取当前工作目录。
cd (change dir)切换目录。若cd后没有指定切换到那个目录,则调回家目录。特别地,cd -表示返回到最近的cd操作前所在目录,相当于回撤到上一个工作目录。
head查看文件最开始的几行,默认为10行,可使用-n 6指定查看前6行。
另外less和more也可以用来查看文件,尤其是文件内容特别多的时候。
1.1.11 查看帮助,获取可用命令行参数
前面使用的命令,有几个用到了参数如ls -l, head -n 6等,需要注意的是命令跟参数之间要有空格。
终端运行man ls可以查看ls所有可用的参数,上下箭头翻页,按q退出查看。(man: manual, 手册)
1.1.12 小结
Linux是多用户操作系统。这一点可以从我们每个人能同时登录到同一台Linux电脑各自进行操作而不相互干扰可以体会出来。大家可以尝试下是否可以看到其它人家目录下的东西。我们后期在权限管理部分会涉及如何开放或限制自己的文件被他人访问。
Linux下所有目录都在根目录下。根目录某种程度上可类比于Windows的我的电脑,第一级子目录类比于
C盘,D盘等 (等我们熟练了,就忘记这个拙劣的类比吧)。使用
mkdir新建目录,cd切换目录,pwd获取当前工作目录,ls查看目录下的内容,cat查看文件,man ls查看ls命令的使用。访问一个文件需要指定这个文件的路径,当前目录下的文件可省略其路径
./,其它目录下则需要指定全路径 (可以是相对路径,也可以是绝对路径)。
1.1.13 做个小测试
- 在家目录下新建文件夹
bin和soft。 - 在
bin和soft目录下各自新建一个文件,名字都是README。 - 在
bin/README文件中写入内容:This folder is used to save executable files。 - 在
soft/README文件中写入内容:This folder is used to save software source files。 - 查看两个
README文件的大小。
1.2 Linux下文件操作
1.2.1 文件按行翻转和按列翻转
两个有意思的命令,tac: 文件翻转,第一行变为最后一行,第二行变为倒数第二行;rev每列反转,第一个字符变为最后一个字符,第二个字符变为倒数第二个字符。
1.2.2 新建文件的n种方式
nano类似于Windows下记事本的功能,nano filename就可以新建一个文件,并在里面写内容;ctrl+x退出,根据提示按Y保存。
vim 功能更强大的文本编辑器。vim filename就可以新建一个文件, 敲击键盘字母i,进入写作模式。写完后,敲击键盘Esc, 退出写作模式,然后输入:w (会显示在屏幕左下角),回车保存。vim的常用方法,后面会有单独介绍。
1.2.3 文件拷贝、移动、重命名、软链
常用的文件操作有移动文件到另一个文件夹、复制文件到另一个文件夹、文件重命名等。
cp (copy): 拷贝文件或文件夹 (cp -r 拷贝文件夹时的参数,递归拷贝).
cp source1 source2 ... target_dir 将一个或多个源文件或者目录复制到已经存在的目标目录。
cp常用参数
-r: 递归拷贝
-f: 强制覆盖
-i: 覆盖前先询问
-p: 保留文件或目录的属性,主要是时间戳
-b: 备份复制,若目标文件存在,先备份之前的,再把新的覆盖过去
-u: 更新复制,若源文件和目标文件都存在,只在源文件的修改时间比较新时才复制
mv (move): 移动文件或文件夹
mv source target, 常用参数有
-f: 强制覆盖
-i: 覆盖前询问
-u: 更新移动
rename: 文件重命名 (常用于批量重命名,不同的系统可能用法略有不同,使用前先man rename查看使用方法)
ln (link): 给文件建立快捷方式 (ln -s source_file target 创建软连接)。
在建立软连接时,原文件要使用全路径。全路径指以/开头的路径。如果希望软链可以让不同的用户访问,不要使用~。
建立软连接,是为了在不增加硬盘存储的情况下,简化文件访问方式的一个办法。把其它文件夹下的文件链接到当前目录,使用时只需要写文件的名字就可以了,不需要再写长串的目录了。
ln命令常用参数
-s: 软连接
-f: 强制创建
../: 表示上一层目录;../../: 表示上面两层目录
pwd (print current/working directory): 输出当前所在的目录
\``为键盘Esc下第一个按键 (与家目录~`符号同一个键),写在反引号内的命令会被运行,运行结果会放置在反引号所在的位置
使用全路径名,尤其使用家目录 ~ 符号时,只限操作用户自身有效。另外不同用户之间建立软连接,需要考虑访问权限问题,任意一层目录都需要可读权限 (目录的可读为rx都有)。
复制、移动或创建软连接时,如果目标已存在,除了使用-f强制覆盖外,还可以使用rm命令删除。
rm可以删除一个或多个文件和目录,也可以递归删除所有子目录,使用时一定要慎重。rm命令删除的文件很难恢复。
rm -rf *: 可以删除当前目录下所有文件和文件夹,慎用。
rm命令常见参数:
-f:强制删除
-i: 删除前询问是否删除
-r: 递归删除
1.2.4 Linux下命令的一些突发事故
命令不全:在命令没有输入完 (引号或括号没有配对),就不小心按下了Enter键,终端会提示出一个>代表命令不完整,这是可以继续输入,也可以ctrl+c终止输入,重新再来。(下面sed命令使用时,还有另外一种命令不全的问题)
文件名输入错误: 多一个字母、少一个字母、大小写问题
所在目录不对: 访问的文件不存在于当前目录,而又没有提供绝对路径, 或软连接失效
1.2.5 了解和操作你的文件
常用的文件内容操作有文件压缩解压缩、文件大小行数统计、文件内容查询等。
gzip: 压缩文件; gunzip: 解压缩文件
wc (word count): 一般使用wc -l获取文件的行数。
获取文件中包含大于号 (>)的行, grep (print lines matching a pattern,对每一行进行模式匹配)。
grep的用法很多,支持正则表达式匹配,这个后面我们会详细讲解。
替换文件中的字符: sed是一个功能强大的文件内容编辑工具,常用于替换、取得行号等操作。现在先有个认识,后面会详细介绍。
| 为管道符,在相邻命令之间传递数据流,表示把上一个命令的输出作为下一个命令的输入。
另外一个方式,去除HAHA,使用cut命令。cut更适合于矩阵操作,去除其中的一列或者多列。但在处理FASTA格式文件时有这么一个妙用。FASTA文件中序列里面是没有任何符号的,而如果名字比较长,则可以指定相应分隔符就行cut,这样既处理了名字,又保留了序列。
-f: 指定取出哪一列,使用方法为-f 2 (取出第2列),-f 2-5 (取出第2-5列),-f 2,5 (取出第2和第5列)。注意不同符号之间的区别。
-d: 设定分隔符, 默认为TAB键。如果某一行没有指定的分隔符,整行都为第一列。
1.2.6 小结和练习
- Linux下文件拷贝、移动、重命名、软连接、压缩、替换等操作。
- Linux下常见问题
ehbio2.fa: 没有那个文件或目录:这个错误通常由什么引起,应该怎么解决?- 若文件
a存在,运行ln a data/b能否成功给a建立软连接? grep '> ehbio.fa的输出是什么?
- 若目标文件存在时,再运行
cp,mv或ln会有什么提示? - 计算某一个Fasta序列中序列的个数。
1.3 Linux终端常用快捷操作
命令或文件名自动补全:在输入命令或文件名的前几个字母后,按
Tab键,系统会自动补全或提示补全上下箭头:使用上下箭头可以回溯之前的命令,增加命令的重用,减少输入工作量
!加之前输入过的命令的前几个字母,快速获取前面的命令ctrl+a回到命令的行首,ctrl+e到命令行尾,(home和end也有类似功能),用于修改命令或注释掉命令!!表示上一条命令。替换上一个命令中的字符,再运行一遍命令,用于需要对多个文件执行同样的命令,又不想写循环的情况
1.4 Linux下的标准输入、输出、重定向、管道
在Linux系统中,有4个特殊的符号,<, >, |, -,在我们处理输入和输出时存在重要但具有迷惑性的作用。
默认Linux的命令的结果都是输出到标准输出,错误信息 (比如命令未找到或文件格式识别错误等) 输出到标准错误,而标准输出和标准错误默认都会显示到屏幕上。
>表示重定向标准输出,> filename就是把标准输出存储到文件filename里面。标准错误还是会显示在屏幕上。
2 >&1 表示把标准错误重定向到标准输出。Linux终端用2表示标准错误,1表示标准输出。
- (短横线):表示标准输入,一般用于1个程序需要多个输入的时候。
< 标准输入,后面可以跟可以产生输出的命令,一般用于1个程序需要多个输入的时候。相比-适用范围更广。
|管道符,表示把前一个命令的输出作为后一个命令的输入,前面也有一些展示例子。用于数据在不同的命令之间传输,用途是减少硬盘存取损耗。
下面我们通过一个程序stdout_error.sh来解释上面的文字 (Bash脚本写作,后面会有专门介绍),内容如下
运行这个脚本
下面看管道符和标准输入的使用。
管道符的更多应用
1.5 Linux文件内容操作
1.5.1 命令组合生成文件
seq: 产生一系列的数字; man seq查看其具体使用。我们这使用seq产生下游分析所用到的输入文件。
1.5.2 文件排序原来有暗仓
sort: 排序,默认按字符编码排序。如果想按数字大小排序,需添加-n参数。
sort常用参数
-n: 数值排序
-h: 人类刻度的数值排序 (2K 1G等)
-r: reverse, 逆序
-c: check, 不排序,查看文件是否已排序好
-k: 指定使用哪列或哪几列排序
-m: 合并已经排序好的文件
-S: 缓冲区大小,用于排序大文件时的分割排序中每次分割的文件大小
-u: 重复行只保留一次
sort -u: 去除重复的行,等同于sort | uniq。
sort file | uniq -d: 获得重复的行。(d=duplication)
sort file | uniq -c: 获得每行重复的次数。
整理下uniq -c的结果,使得原始行在前,每行的计数在后。
awk是一个强大的文本处理工具,其处理数据模式为按行处理。每次读入一行,进行操作。
OFS: 输出文件的列分隔符 (output file column separtor);FS为输入文件的列分隔符 (默认为空白字符);awk中的列从第1到n列,分别记录为$1,$2…$n;BEGIN表示在文件读取前先设置基本参数;与之相对应的是END,只文件读取完成之后进行操作;- 不以
BEGIN,END开头的{}就是文件读取、处理的部分。每次对一行进行处理。后面会详细讲解。
对两列文件,按照第二列进行排序, sort -k2,2n。
两个暗仓:
- sort默认文件列分隔符是所有空字符,若同时存在
和 会有非预期结果。 sort -t '\t'是错误用法,TAB键的正确输入方式是:先按<ctrl+v>再按。
1.5.3 实战FASTA序列提取 [#fasta_extract}
生成单行序列FASTA文件,提取特定基因的序列,最简单的是使用grep命令。
grep在前面也提到过,以后还会经常提到,主要用途是匹配文件中的字符串,以此为基础,进行一系列的操作。如果会使用正则表达式,将会非常强大。正则表达式版本很多,几乎每种语言都有自己的规则,后面会详细展开。
多行FASTA序列提取要麻烦些,一个办法就是转成单行序列,用上面的方式处理。
sed和tr都为最常用的字符替换工具。
>SOX2 ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGGAC >POU5F1 CGGAAGGTAGTCGTCAGTGCAGCGAGTCCGT CGGAAGGTAGTCGTCAGTGCAGCGAGTCC >NANOG ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGG ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGGACTGT
# >号前面加换行符
ct@ehbio:~$ cat test.fasta | tr '\n' '\t' | sed 's/\t>/\n>/g'
>SOX2 ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGGAC
>POU5F1 CGGAAGGTAGTCGTCAGTGCAGCGAGTCCGT CGGAAGGTAGTCGTCAGTGCAGCGAGTCC
>NANOG ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGG ACGAGGGACGCATCGGACGACTGCAGGACTGTC ACGAGGGACGCATCGGACGACTGCAGGACTGT
# 先把第一个TAB键变为换行符,实现序列名字和序列的分离
# 再去掉序列中所有的TAB键
ct@ehbio:~$ cat test.fasta | tr '\n' '\t' | sed 's/\t>/\n>/g' \
| sed 's/\t/\n/' | sed 's/\t//g' >test.oneline.fa
>SOX2
ACGAGGGACGCATCGGACGACTGCAGGACTGTCACGAGGGACGCATCGGACGACTGCAGGACTGTCACGAGGGACGCATCGGACGACTGCAGGAC
>POU5F1
CGGAAGGTAGTCGTCAGTGCAGCGAGTCCGTCGGAAGGTAGTCGTCAGTGCAGCGAGTCC
>NANOG
ACGAGGGACGCATCGGACGACTGCAGGACTGTCACGAGGGACGCATCGGACGACTGCAGGACGAGGGACGCATCGGACGACTGCAGGACTGTCACGAGGGACGCATCGGACGACTGCAGGACTGT
或者简单点,直接用前面的awk略微做下修改。
1.6 Linux下的查找命令 - 文件哪里跑
查找是我们每天都在做的事情,早上醒来找下手机,出门之前查下公交,坐下之后查下资料,分析数据查下模式。
查找文件,查找信息,查找错误是应用起来更为具体的一些工作,而Linux命令行为我们提供了很多快捷强大的查找方式。
1.6.1 命令/可执行程序查找 - 定位脚本的位置
whereis program_name: 会在系统默认安装目录(一般是有root权限时默认安装的软件)和$PATH, $MANPATH指定的目录中查找二进制文件、源码、文档中包含给定查询关键词的文件。(默认目录有 /bin, /sbin, /usr/bin, /usr/lib, /usr/local/man等类似路径)
which program_name: 会给出所有在环境变量中的程序的路径,一来方便知道运行的程序在哪,二来方便修改。比如vim `which sp_pheatmap.sh`就可以直接修改绘制热图的脚本,cp \which sp_pheatmap.sh` .`可以直接把源码拷贝到当前目录,省去了写全路径的麻烦。
如果运行which bwa,系统返回是 /usr/bin/which: no bwa in (/home/usr/bin:/bin)则说明bwa没有安装或安装后没有放置在环境变量中,不可以直接写名字调用。
1.6.2 locate普通文件快速定位
locate是快速查找定位文件的好方法,但其依赖于updatedb建立的索引。而updatedb一般是每天运行一次,所以当天新建的文件是索引不到的。如果有根用户权限,可以手动运行updatedb做个更新,然后再locate bwa。(个人用户也可以构建自己的updatedb, 使用locate在局部环境中查找。)
ct@ehbio:~$ locate R.sys
/soft/R.sys1.6.3 find让文件无处可逃 find
find / -name bwa可以搜索根目录下所有名字为bwa的文件
运行上面的命令时会输出很多Permission denied,是因为 作为普通用户,无权限访问一些目录,因此会有提示输出,可以使用find / -name bwa 2>/dev/null重定向标准错误到空设备,报错信息就被扔掉了,还不影响正常输出。
ct@ehbio:~$ find / -name R 2>/dev/null
/usr/bin/R
/usr/lib/rstudio-server/R
/usr/share/groff/1.22.2/font/devascii/R
/usr/share/groff/1.22.2/font/devhtml/R
/usr/share/groff/1.22.2/font/devlatin1/R
/usr/share/groff/1.22.2/font/devutf8/R
/usr/local/bin/R
/usr/local/lib64/R
/usr/local/lib64/R/share/R
/usr/local/lib64/R/bin/R1.6.3.1 按时间查找
我们开发的在线画图网站 (www.ehbio.com/ImageGP),为了追踪每天用户使用时碰到了什么问题,需要每天定时去查看日志。
这个命令find . -name *.log -mmin -60可以查看当前目录下(包括所有子目录)一小时内修改的日志文件。再配合head就可以查看每个日志文件的内容,以方便查看使用过程中出现了哪些错误,如何增加提示或修改画图程序。
正是有了这个利器,前台的错误提示中才出现了这么一句话,如果您核对后数据和参数没问题,请过1天再进行尝试。若是程序问题,我们通常会在1天内修复。
当然后台数据都是用时间戳存储的,而且若无报错,数据会直接删掉,有报错的才会保留日志,不会泄露用户信息,这点大家不用担心。
现在画图网站越来越稳定,出现的问题越来越少,前台提示也越来越完善,希望大家使用时多看下提示,查看日志的频率也少了,就使用find . -name *.log -mtime -1查看从现在起24小时内的日志了。
这个也有个问题,每次查看的时间可能不一致,会漏查或有重叠,于是在某次查看完日志后,使用touch check在当前目录下新建了个空文件。以后再查日志文件时,只要使用find . -name *.log -newer check就可以获得所有上次查看过之后的新日志。每次查看完之后,都做个书签,就方便多了。
慢慢发现有空日志文件, 使用find . -name *.log -newer check -size +0过滤掉, 只保留大小大于0的文件。就这样在小伙伴聪明勤奋地维持下,我们绘图网站为7万多用户提供了近100万次服务 (画图手册 | ImageGP:今天你“plot”了吗?)。
1.6.3.2 按类型和大小查找 {$find_by_type_size}
如果我想得到当前目录下所有png和jpg照片呢?
使用 find . \( -name "*.png" -o -name "*.jpg" \) | less
或 find . -regex ".*\(\.png\|\.jpg\)$"
find . -type f -size +100G可以获取大小超过100G的文件。
1.6.3.3 限制查找深度
只看当前目录2层子目录内的文件find . -maxdepth 2 -name *.log。
查看不是log结尾的文件find . -not -name *.log。还有更多组合操作,详见find文档。
1.6.4 按文件内容查找 grep
find可以查找包含某句话的文件吗? 还是拿我们的日志说事吧,find . -name *.log -exec grep -l 'Error' {} \;就可以返回所有包含Error单词的文件名。
find . -name *.log | xargs grep -l 'Error'也可以。
grep -rl 'Error' *也可以,不加-l还可以顺便返回匹配的行。
匹配行的前后行
grep -A 5 -B 1 'Bioinfo' ehbio.log可以查看匹配行的前1行(B, before)和后5行(A, after)。
匹配次数
grep -c 'Bioinfo' ehbio.log可以统计包含Bioinfo的行数
grep -ci 'Bioinfo' ehbio.log则会在匹配时忽略大小写。
统计FASTA序列中的序列数 grep '^>' ehbio.fa
统计FASTQ序列中的序列数 grep '^+$' ehbio.fq。(^表示以什么开头,$表示以什么结尾)。
获取未匹配行
grep -v 'Bioinfo' ehbio.log,读读手册(man grep),可以看到更多参数使用。
序列提取
假设有个基因列表文件 (ID),有个单行序列的FASTA文件 (ehbio.fa), 运行如下命令grep -A 1 -Fw -f id ehbio.fa | grep -v -- '--'就可以批量提取序列了。
-f id表示把id文件中的每一行作为一个匹配模式。-F表示匹配模式作为原始字符串,而非正则表达式,这是以防有特殊字符被解析。-w则表示作为一个单词匹配,即假如id中有Sox2,那么它会匹配Sox2,也会匹配Sox21;如果加了-w,则不会匹配Sox21。
更好的序列批量提取见 awk的使用。
模式匹配
grep强大的功能是支持正则匹配,默认使用基本正则表达式,-E使用扩展的正则表达式,-P使用perl格式的正则表达式。
比如想去掉文件中所有的空行grep -v '^$' ehbio.fa >ehbio.clean.fa;
从公众号文章中搜索跟文章写作相关的文章 grep 'writ.*' *.md (可以匹配write, writing等字);
正则表达式就比较多了,具体可以看http://mp.weixin.qq.com/s/4lUiZ60-aXLilRk9--iQhA。
1.7 一句话加速grep近30倍
最近做一个项目,需要从表达矩阵中提取单个特定基因的表达值。最开始时文件比较小,使用awk单个读取处理也很快,但后来数据多了,从一个1.2 G的文件中提取单个基因的表达需要30 s,用grep来写需要25 S,这在平时写程序是可以接受的,但在网站上是接受不了的。所以就想着如何优化一下。
探索下来优化也很简单,把grep换为LC_ALL=C grep再加其它参数速度就快了近30倍,把时间控制在1 s左右。
下面是整个探索过程 (写这篇总结文章是在早晨,服务器不繁忙,所以下面的示例中只能看出来快了5倍左右。这也表明不加LC_All=C时grep受服务器负载影响较大,加了之后则几乎不受影响。)
1.7.1 获取单基因表达量
查看下文件大小
ls -sh 334d41a7-e34a-4bab-841c-eb07bd84513f.txt
# 1.2G 334d41a7-e34a-4bab-841c-eb07bd84513f.txt查看下文件内容
head 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | cut -f 1,2
# Rnu2-1 -0.52
# Tmsb4Xp6 11.81
# S100A14 1.99
# Krt17 1.26
# Aldh1A1 6.92
# Fxyd3 0.56
# Rnu2-2P 0.35
# Rarres1 6.03
# Rnvu1-7 9.53
# Lcn2 3.44假设基因名字大小写一致时使用awk提取其表达信息,用时14 s。
time awk '{if($1=="Tmsb4Xp6") print $2;}' 334d41a7-e34a-4bab-841c-eb07bd84513f.txt >1
real 0m14.569s
user 0m12.943s
sys 0m0.626s实际上大小写可能不一致而需要转换,耗时17 s。
time awk '{if(tolower($1)=="tmsb4xp6") print $2;}' 334d41a7-e34a-4bab-841c-eb07bd84513f.txt >2
real 0m17.638s
user 0m17.031s
sys 0m0.595s采用grep命令提取 (-i忽略大小写),用时5 s。
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | grep -i 'Tmsb4Xp6' >4
real 0m5.454s
user 0m5.134s
sys 0m1.272s上面的grep是全句匹配,想着加上^匹配行首是否会减少匹配量,速度能快一些,效果不明显,用时4 s。
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | grep -iP '^Tmsb4Xp6' >5
real 0m4.262s
user 0m3.984s
sys 0m1.233sgrep是处理匹配关系,获得的是包含关键词但不一定全等于关键词,加一个-w参数,匹配更精确些,耗时6.7 s。
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | grep -iPw '^Tmsb4Xp6' >6
real 0m6.723s
user 0m6.390s
sys 0m1.348s从上面来看,采用正则限定并不能提速,还是采用固定字符串方式提取,速度也差不多,耗时5 s。(fgrep等同于grep -F)
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | fgrep -i 'Tmsb4Xp6' >7
real 0m5.496s
user 0m5.128s
sys 0m1.366s主角出场,加上LC_ALL=C后,速度明显提升了,只需要1 s时间。
time LC_ALL=C fgrep -i '^Tmsb4Xp6' 334d41a7-e34a-4bab-841c-eb07bd84513f.txt >8
real 0m1.027s
user 0m0.671s
sys 0m0.355s多次测试下来,发现添加LC_ALL=C后grep命令快了很多,而且多次测试速度都很稳定 (不论服务器是繁忙还是空闲)。这里面的原理是涉及字符搜索空间的问题,我们操作的文件只包含字母、字符、数字,没有中文或其它复杂符号时都是适用的,具体原理和更多评估可查看文末的两篇参考链接,了解更多信息。
为了简化应用,我们可以alias grep='LC_ALL=C grep' (把这句话放到~/.bashrc或~/.bahs_profile里面),后续再使用grep时就可以直接得到速度提升了。
time grep -F -i '^Tmsb4Xp6' 334d41a7-e34a-4bab-841c-eb07bd84513f.txt
real 0m1.013s
user 0m0.679s
sys 0m0.334s1.7.2 那如果获取多个基因怎么操作呢?
一个方式是使用正则表达式,多个基因一起传递过去,分别匹配,耗时4.6 s。
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | LC_ALL=C grep -iP 'Tmsb4Xp6|Sox1|Sox2|Sox3'
real 0m4.654s
user 0m4.366s
sys 0m1.227s或者还是使用固定字符串查找模式,把所有基因每行一个写入文件a,然后再去匹配,耗时2.5 s,且测试发现在基因数目少于10时(这是通常的应用场景),基因多少影响不大 (这也说明能用固定字符串查找时最好显示指定)。
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | LC_ALL=C fgrep -i -f a >11
real 0m2.539s
user 0m2.191s
sys 0m1.249s这里还比较了另外2个号称比grep快的命令ag和rg在这个应用场景没体现出性能优势。
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | LC_ALL=C ag -i '^Tmsb4Xp6|Sox1|Sox2|Sox3' >10
real 0m11.281s
user 0m9.713s
sys 0m5.326s
time cat 334d41a7-e34a-4bab-841c-eb07bd84513f.txt | rg -iF -f a >12
real 0m4.337s
user 0m3.444s
sys 0m2.787s1.8 监控程序的运行时间和资源占用
- 监测命令的运行时间
time command
ct@ehbio:~$ time sleep 5
real 0m5.003s # 程序开始至结束的时间,包括其它进程占用的时间片和IO时间
user 0m0.001s # 进程真正执行占用CPU的时间,
sys 0m0.002s # 进程在内核中调用所消耗的CPU时间
user+sys是进程实际的CPU时间。如果多线程执行,这个时间可能大于Real。如果IO是瓶颈,则real会大于user+sys (单线程)。- 查看正在运行的命令和其资源使用
top
- top输出界面第一行主要信息是负载显示,分别是1分钟、5分钟、15分钟前到现在的任务队列的平均长度。
- 一般与CPU数目相当为好,过大系统负载超额,反应慢。
- 在top输出界面输入
u, 会提示输入用户名,以查看某个用户的进程。 - 重点关注的是%MEM列,查看系统占用的内存是否超出。
ct@ehbio:~$ top -a #按内存排序显示
top - 09:02:11 up 224 days, 8:34, 30 users, load average: 40, 33, 28
Tasks: 1561 total, 1 running, 1550 sleeping, 0 stopped, 10 zombie
Cpu(s): 0.6%us, 0.2%sy, 0.0%ni, 99.2%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 2642768880k total, 2094619800k used, 548149080k free, 4310240k buffers
Swap: 86472700k total, 73226016k used, 13246684k free, 193383748k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32527 ct 20 0 2631m 1.7g 1332 S 0.0 0.7 100:34.87 rsem-run-em
29273 ct 20 0 4094m 692m 3396 S 0.0 0.3 45:18.83 java -Xmx1000m
40148 mysql 20 0 21.9g 606m 6116 S 1.3 0.2 2536:06 /usr/sbin/mysqld
31040 ct 20 0 1887m 77m 2604 S 0.3 0.0 180:43.16 [celeryd: - 查看系统进程
ps auwx | grep 'process_name'
1.9 References
- 原文链接 http://blog.genesino.com//2017/06/bash1/
- 微信公众号 http://mp.weixin.qq.com/s/yKP1Kboji9N4p2Sl1Ovj0Q
- Linux-总目录
- Linux-文件和目录
- Linux-文件操作
- Linux文件内容操作
- Linux-环境变量和可执行属性
- Linux - 管道、标准输入输出
- Linux - 命令运行监测和软件安装
- Linux-常见错误和快捷操作
- Linux-文件列太多,很难识别想要的信息在哪列;别焦急,看这里。
- Linux-文件排序和FASTA文件操作
- Linux-应用Docker安装软件
- Linux服务器数据定期同步和备份方式
- VIM的强大文本处理方法
- Linux - Conda软件安装方法
- 查看服务器配置信息
- Linux - SED操作,awk的姊妹篇
- Linux - 常用和不太常用的实用awk命令
- Bash概论 - Linux系列教程补充篇
- 原来你是这样的软连接
- 一网打进Linux下那些查找命令
- 有了这些,文件批量重命名还需要求助其它工具吗?