7 预测哪个阅读指标对吸引关注影响最大
公众号后台收集了发表过文章的各项阅读指标包括:内容标题,总阅读人数,总阅读次数,总分享人数,总分享次数,阅读后关注人数,送达阅读率,分享产生阅读次数,首次分享率,每次分享带来阅读次数,阅读完成率。
我们尝试利用机器学习中的随机森林算法预测下,是否存在某些指标可以预测吸引的关注人数。
7.1 数据格式和读入数据
数据集包括1588篇文章的9个统计指标。
- 阅读统计矩阵: WeChatOfficialAccount.txt
- 阅读后关注人数:WeChatOfficialAccountFollowers.txt
feature_file <- "data/WeChatOfficialAccount.txt"
metadata_file <- "data/WeChatOfficialAccountFollowers.txt"
feature_mat <- read.table(feature_file, row.names = 1, header = T, sep="\t", stringsAsFactors =T)
# 处理异常的特征名字
# rownames(feature_mat) <- make.names(rownames(feature_mat))
metadata <- read.table(metadata_file, row.names=1, header=T, sep="\t", stringsAsFactors =T)
dim(feature_mat)## [1] 1588 9阅读统计表示例如下:
feature_mat[1:4,1:5]## TotalReadingPeople TotalReadingCounts TotalSharingPeople TotalSharingCounts
## 1 8278 11732 937 1069
## 2 8951 12043 828 929
## 3 18682 22085 781 917
## 4 4978 6166 525 628
## ReadingRate
## 1 0.0847
## 2 0.0979
## 3 0.0608
## 4 0.0072Metadata表示例如下
head(metadata)## FollowersAfterReading
## 1 227
## 2 188
## 3 119
## 4 116
## 5 105
## 6 1007.1.1 样品筛选和排序
样本表和表达表中的样本顺序对齐一致也是需要确保的一个操作。
feature_mat_sampleL <- rownames(feature_mat)
metadata_sampleL <- rownames(metadata)
common_sampleL <- intersect(feature_mat_sampleL, metadata_sampleL)
# 保证表达表样品与METAdata样品顺序和数目完全一致
feature_mat <- feature_mat[common_sampleL,,drop=F]
metadata <- metadata[common_sampleL,,drop=F]7.1.2 判断是分类还是回归
前面读数据时已经给定了参数stringsAsFactors =T,这一步可以忽略了。
- 如果group对应的列为数字,转换为数值型 - 做回归
- 如果group对应的列为分组,转换为因子型 - 做分类
# R4.0之后默认读入的不是factor,需要做一个转换
# devtools::install_github("Tong-Chen/ImageGP")
library(ImageGP)
# 此处的FollowersAfterReading根据需要修改
group = "FollowersAfterReading"
# 如果group对应的列为数字,转换为数值型 - 做回归
# 如果group对应的列为分组,转换为因子型 - 做分类
if(numCheck(metadata[[group]])){
if (!is.numeric(metadata[[group]])) {
metadata[[group]] <- mixedToFloat(metadata[[group]])
}
} else{
metadata[[group]] <- as.factor(metadata[[group]])
}7.1.3 随机森林初步分析
library(randomForest)
# 查看参数是个好习惯
# 有了前面的基础概述,再看每个参数的含义就明确了很多
# 也知道该怎么调了
# 每个人要解决的问题不同,通常不是别人用什么参数,自己就跟着用什么参数
# 尤其是到下游分析时
# ?randomForest
# 查看源码
# randomForest:::randomForest.default加载包之后,直接分析一下,看到结果再调参。
# 设置随机数种子,具体含义见 https://mp.weixin.qq.com/s/6plxo-E8qCdlzCgN8E90zg
set.seed(304)
# 直接使用默认参数
rf <- randomForest(feature_mat, metadata[[group]])查看下初步结果, 随机森林类型判断为分类,构建了500棵树,每次决策时从随机选择的94个基因中做最优决策 (mtry),OOB估计的错误率是9.8%,挺高的。
分类效果评估矩阵Confusion matrix,显示normal组的分类错误率为0.06,tumor组的分类错误率为0.13。
rf##
## Call:
## randomForest(x = feature_mat, y = metadata[[group]])
## Type of random forest: regression
## Number of trees: 500
## No. of variables tried at each split: 3
##
## Mean of squared residuals: 39.82736
## % Var explained: 74.91观察下模型对训练集的预测效果,看上去一致性还可以。
library(ggplot2)
followerDF <- data.frame(Real_Follower=metadata[[group]], Predicted_Follower=predict(rf, newdata=feature_mat))
sp_scatterplot(followerDF, xvariable = "Real_Follower", yvariable = "Predicted_Follower",
smooth_method = "auto") + coord_fixed(1)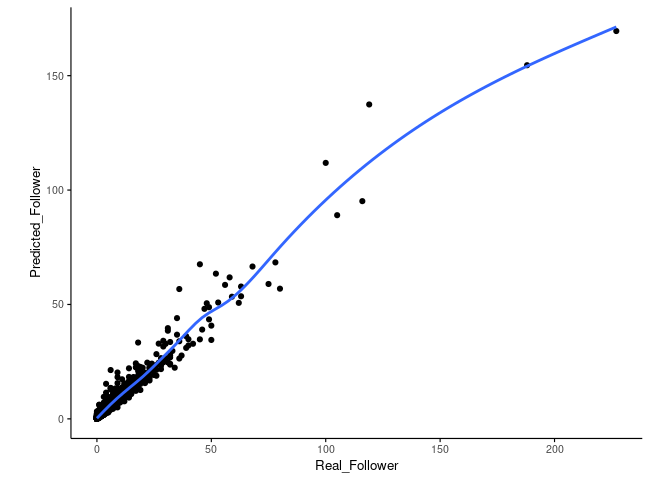
7.2 随机森林标准操作流程
7.2.1 拆分训练集和测试集
library(caret)
seed <- 1
set.seed(seed)
train_index <- createDataPartition(metadata[[group]], p=0.75, list=F)
train_data <- feature_mat[train_index,]
train_data_group <- metadata[[group]][train_index]
test_data <- feature_mat[-train_index,]
test_data_group <- metadata[[group]][-train_index]dim(train_data)## [1] 1192 9dim(test_data)## [1] 396 97.2.2 Boruta特征选择鉴定关键分类变量
# install.packages("Boruta")
library(Boruta)
set.seed(1)
boruta <- Boruta(x=train_data, y=train_data_group, pValue=0.01, mcAdj=T,
maxRuns=300)
boruta## Boruta performed 14 iterations in 4.777348 secs.
## 8 attributes confirmed important: AverageReadingCountsForEachSharing,
## FirstSharingRate, ReadingRate, TotalReadingCounts,
## TotalReadingCountsOfSharing and 3 more;
## 1 attributes confirmed unimportant: ReadingFinishRate;查看下变量重要性鉴定结果(实际上面的输出中也已经有体现了),8个重要的变量,0个可能重要的变量 (tentative variable, 重要性得分与最好的影子变量得分无统计差异),1个不重要的变量。
table(boruta$finalDecision)##
## Tentative Confirmed Rejected
## 0 8 1绘制鉴定出的变量的重要性。变量少了可以用默认绘图,变量多时绘制的图看不清,需要自己整理数据绘图。
定义一个函数提取每个变量对应的重要性值。
library(dplyr)
boruta.imp <- function(x){
imp <- reshape2::melt(x$ImpHistory, na.rm=T)[,-1]
colnames(imp) <- c("Variable","Importance")
imp <- imp[is.finite(imp$Importance),]
variableGrp <- data.frame(Variable=names(x$finalDecision),
finalDecision=x$finalDecision)
showGrp <- data.frame(Variable=c("shadowMax", "shadowMean", "shadowMin"),
finalDecision=c("shadowMax", "shadowMean", "shadowMin"))
variableGrp <- rbind(variableGrp, showGrp)
boruta.variable.imp <- merge(imp, variableGrp, all.x=T)
sortedVariable <- boruta.variable.imp %>% group_by(Variable) %>%
summarise(median=median(Importance)) %>% arrange(median)
sortedVariable <- as.vector(sortedVariable$Variable)
boruta.variable.imp$Variable <- factor(boruta.variable.imp$Variable, levels=sortedVariable)
invisible(boruta.variable.imp)
}boruta.variable.imp <- boruta.imp(boruta)
head(boruta.variable.imp)## Variable Importance finalDecision
## 1 AverageReadingCountsForEachSharing 4.861474 Confirmed
## 2 AverageReadingCountsForEachSharing 4.648540 Confirmed
## 3 AverageReadingCountsForEachSharing 6.098471 Confirmed
## 4 AverageReadingCountsForEachSharing 4.701201 Confirmed
## 5 AverageReadingCountsForEachSharing 3.852440 Confirmed
## 6 AverageReadingCountsForEachSharing 3.992969 Confirmed只绘制Confirmed变量。从图中可以看出重要性排名前4的变量都与“分享”相关 (分享产生阅读次数,总分享人数,总分享次数,首次分享率),文章被分享对于增加关注是很重要的。
library(ImageGP)
sp_boxplot(boruta.variable.imp, melted=T, xvariable = "Variable", yvariable = "Importance",
legend_variable = "finalDecision", legend_variable_order = c("shadowMax", "shadowMean", "shadowMin", "Confirmed"),
xtics_angle = 90, coordinate_flip =T)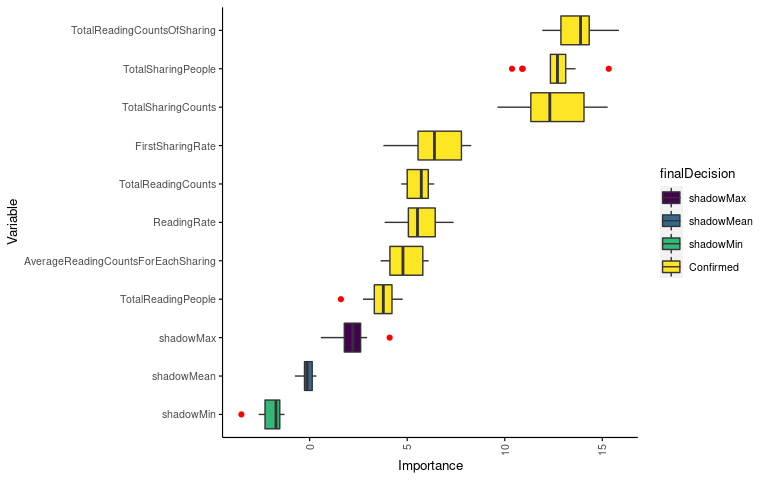
提取重要的变量和可能重要的变量
boruta.finalVarsWithTentative <- data.frame(Item=getSelectedAttributes(boruta, withTentative = T), Type="Boruta_with_tentative")data <- cbind(feature_mat, metadata)
variableFactor <- rev(levels(boruta.variable.imp$Variable))
sp_scatterplot(data, xvariable = group, yvariable = variableFactor[1], smooth_method = "auto")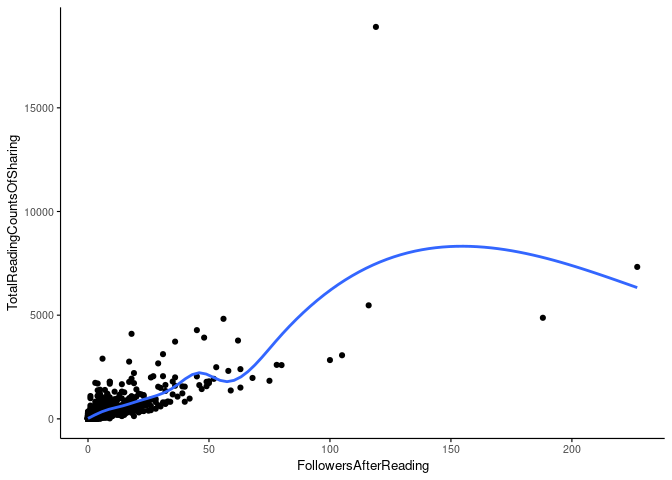 因为变量不多,也可以用
因为变量不多,也可以用ggpairs看下所有变量之间,以及它们与响应变量的相关性怎样?
library(GGally)
ggpairs(data, progress = F)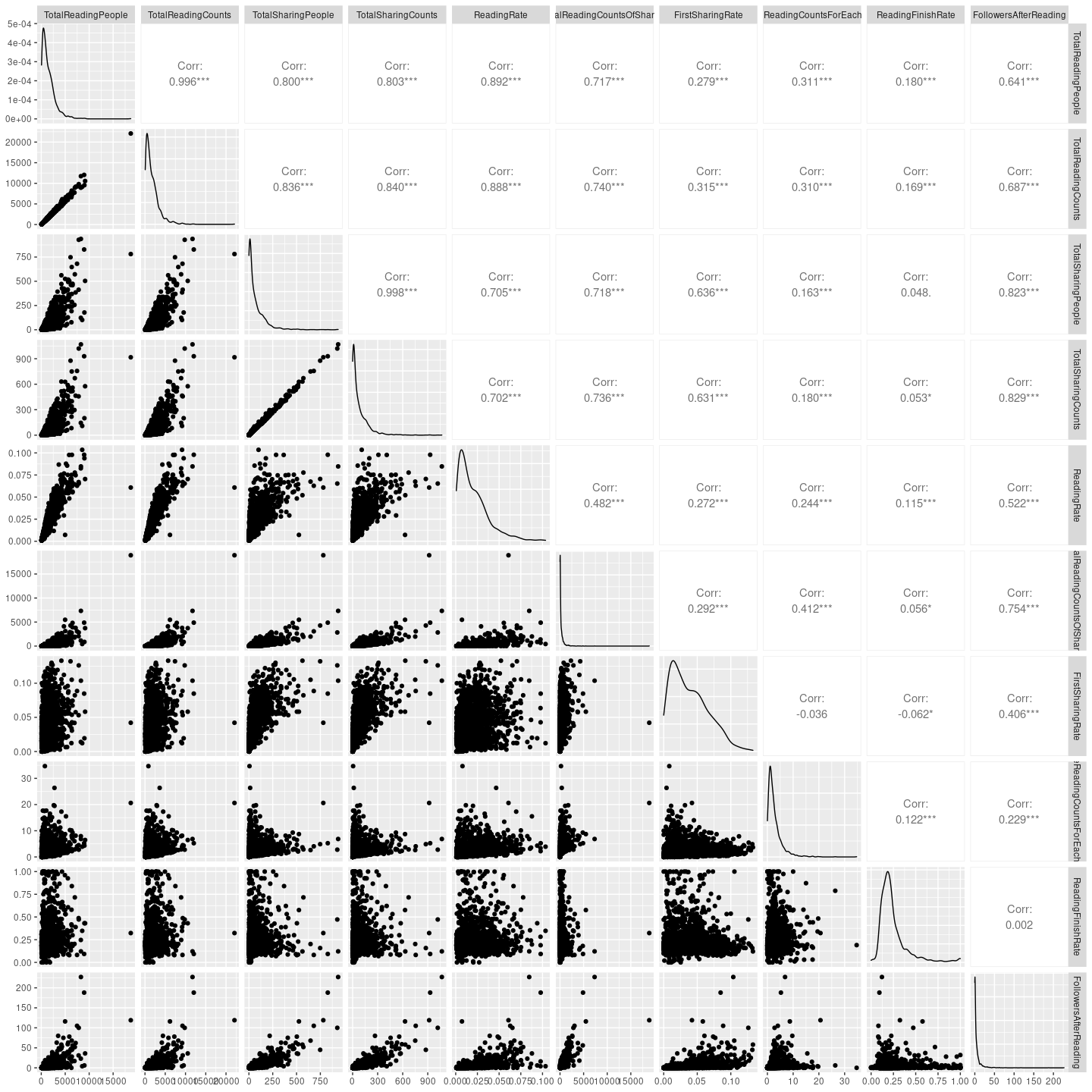
7.2.3 交叉验证选择参数并拟合模型
定义一个函数生成一些列用来测试的mtry (一系列不大于总变量数的数值)。
generateTestVariableSet <- function(num_toal_variable){
max_power <- ceiling(log10(num_toal_variable))
tmp_subset <- c(unlist(sapply(1:max_power, function(x) (1:10)^x, simplify = F)), ceiling(max_power/3))
#return(tmp_subset)
base::unique(sort(tmp_subset[tmp_subset<num_toal_variable]))
}
# generateTestVariableSet(78)选择关键特征变量相关的数据
# 提取训练集的特征变量子集
boruta_train_data <- train_data[, boruta.finalVarsWithTentative$Item]
boruta_mtry <- generateTestVariableSet(ncol(boruta_train_data))使用 Caret 进行调参和建模
library(caret)
if(file.exists('rda/wechatRegression.rda')){
borutaConfirmed_rf_default <- readRDS("rda/wechatRegression.rda")
} else {
# Create model with default parameters
trControl <- trainControl(method="repeatedcv", number=10, repeats=5)
seed <- 1
set.seed(seed)
# 根据经验或感觉设置一些待查询的参数和参数值
tuneGrid <- expand.grid(mtry=boruta_mtry)
borutaConfirmed_rf_default <- train(x=boruta_train_data, y=train_data_group, method="rf",
tuneGrid = tuneGrid, #
metric="RMSE", #metric='Kappa'
trControl=trControl)
saveRDS(borutaConfirmed_rf_default, "rda/wechatRegression.rda")
}
borutaConfirmed_rf_default## Random Forest
##
## 1192 samples
## 8 predictor
##
## No pre-processing
## Resampling: Cross-Validated (10 fold, repeated 5 times)
## Summary of sample sizes: 1073, 1073, 1073, 1072, 1073, 1073, ...
## Resampling results across tuning parameters:
##
## mtry RMSE Rsquared MAE
## 1 6.441881 0.7020911 2.704873
## 2 6.422848 0.7050505 2.720557
## 3 6.418449 0.7052825 2.736505
## 4 6.431665 0.7039496 2.742612
## 5 6.453067 0.7013595 2.754239
## 6 6.470716 0.6998307 2.758901
## 7 6.445304 0.7020575 2.756523
##
## RMSE was used to select the optimal model using the smallest value.
## The final value used for the model was mtry = 3.绘制准确性随超参的变化曲线
plot(borutaConfirmed_rf_default)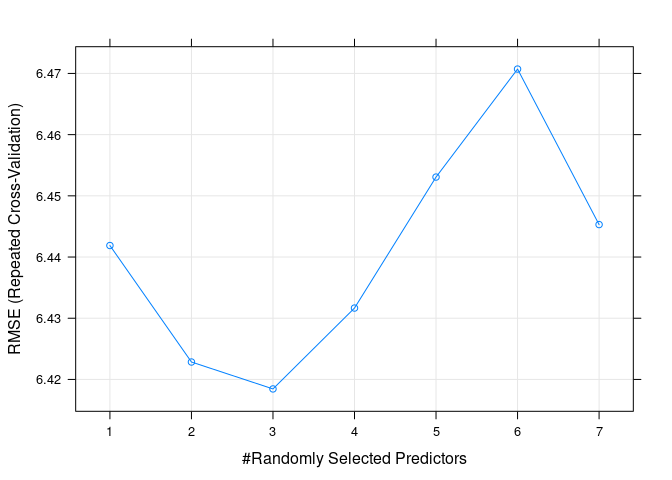
绘制贡献最高的 20 个变量 (Boruta评估的变量重要性跟模型自身评估的重要性略有不同)
dotPlot(varImp(borutaConfirmed_rf_default))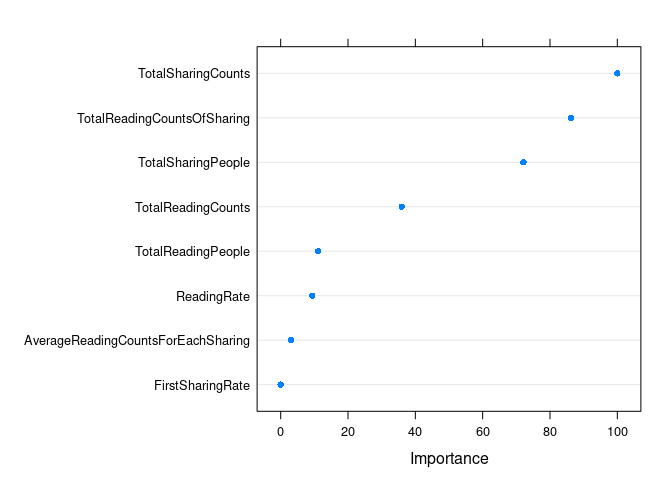
提取最终选择的模型,评估其效果。
# borutaConfirmed_rf_default_finalmodel <- borutaConfirmed_rf_default$finalModel首先采用训练数据集评估构建的模型的训练效果,RMSE=3.1,Rsquared=0.944,还是挺不错的。
# 获得模型结果评估参数
predictions_train <- predict(borutaConfirmed_rf_default, newdata=train_data)
postResample(pred = predictions_train, obs = train_data_group)## RMSE Rsquared MAE
## 3.1028533 0.9440182 1.1891391采用测试数据评估模型的预测效果,RMSE=6.2,Rsquared=0.825,还可以。后续用下其它方法看看能否提高。
predictions_train <- predict(borutaConfirmed_rf_default, newdata=test_data)
postResample(pred = predictions_train, obs = test_data_group)## RMSE Rsquared MAE
## 6.2219834 0.8251457 2.7212806library(ggplot2)
testfollowerDF <- data.frame(Real_Follower=test_data_group, Predicted_Follower=predictions_train)
sp_scatterplot(testfollowerDF, xvariable = "Real_Follower", yvariable = "Predicted_Follower",
smooth_method = "auto") + coord_fixed(1)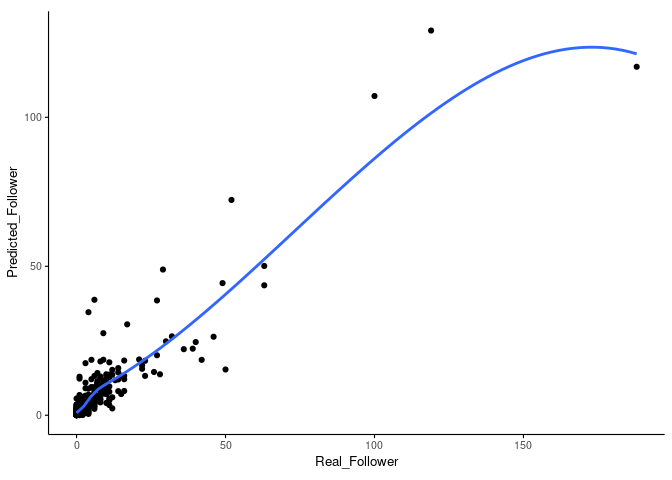
head(test_data)## TotalReadingPeople TotalReadingCounts TotalSharingPeople TotalSharingCounts
## 2 8951 12043 828 929
## 3 18682 22085 781 917
## 6 7826 9804 928 1020
## 11 3222 4159 338 414
## 12 5611 7088 493 533
## 18 7009 8918 572 671
## ReadingRate TotalReadingCountsOfSharing FirstSharingRate
## 2 0.0979 4875 0.0848
## 3 0.0608 18903 0.0421
## 6 0.0653 2835 0.1261
## 11 0.0338 2398 0.0946
## 12 0.0633 1508 0.0861
## 18 0.0777 1930 0.0823
## AverageReadingCountsForEachSharing ReadingFinishRate
## 2 5.2476 0.0929
## 3 20.6140 0.3229
## 6 2.7794 0.4725
## 11 5.7923 0.1628
## 12 2.8293 0.0911
## 18 2.8763 0.71587.3 随机森林回归的不足
随机森林回归模型预测出的值不会超出训练集中响应变量的取值范围,不能用于外推。
可以使用Regression-Enhanced Random Forests (RERFs)作为一个解决方案。
7.4 References
- https://medium.com/swlh/random-forest-and-its-implementation-71824ced454f
- Great concept explanation and illustrations https://neptune.ai/blog/random-forest-regression-when-does-it-fail-and-why
- https://levelup.gitconnected.com/random-forest-regression-209c0f354c84
- https://rpubs.com/Isaac/caret_reg
- https://stats.stackexchange.com/questions/88920/how-to-create-roc-curve-to-assess-the-performance-of-regression-models
RandomForestForOutliers https://stats.stackexchange.com/questions/187200/how-are-random-forests-not-sensitive-to-outliers?rq=1